同時發佈於知乎
TL;DR: 入聲字的情感與舒聲字無明顯差別。
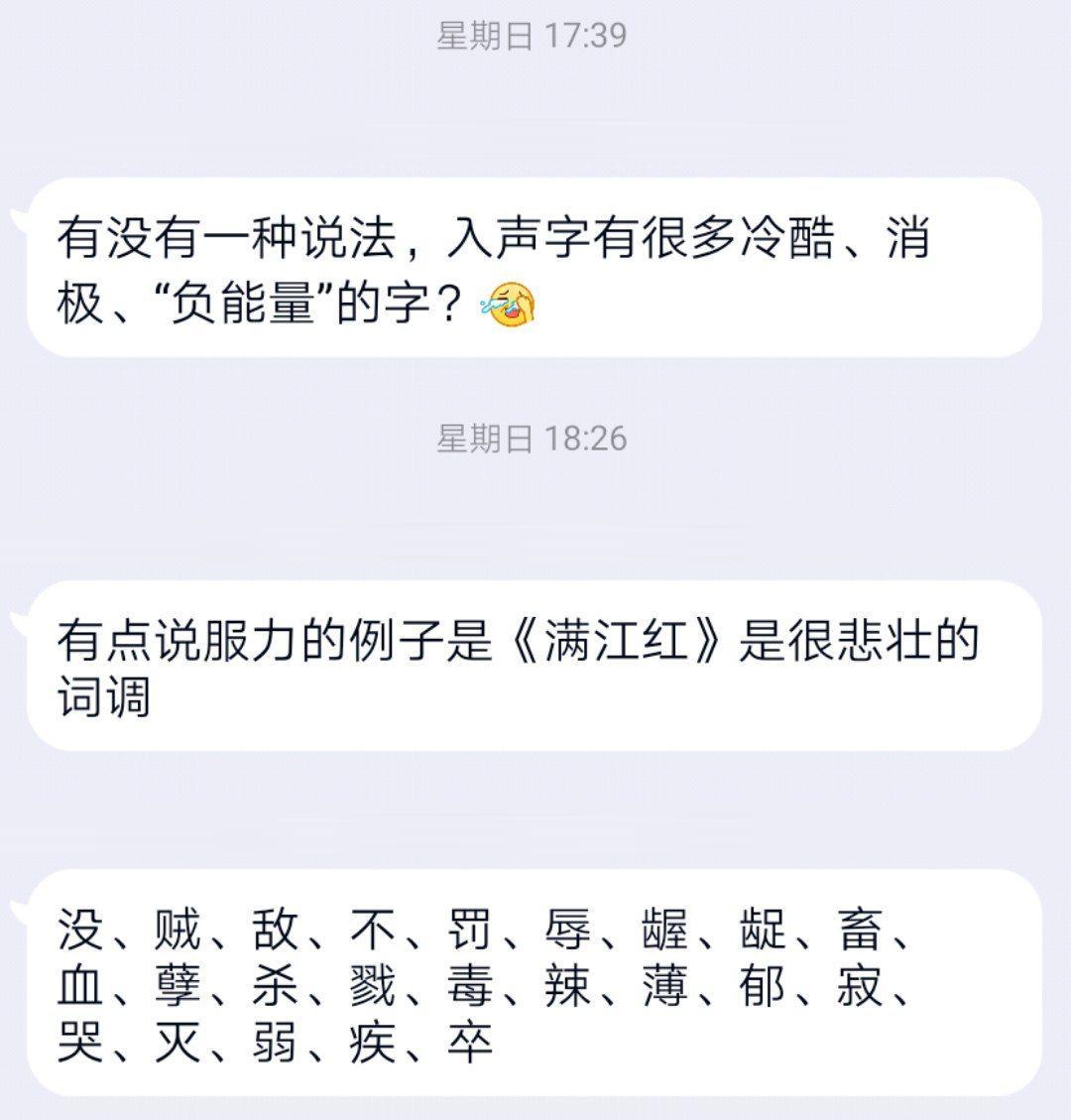
上次羣友提出了一個問題:「有沒有一種説法,入聲字有很多冷酷、消極、負能量的字?」
為了解決這個問題,我決定使用情感分析模型。
在 NLP 中,情感分析是文本分類的一個分支,是對帶有情感色彩(褒義貶義/正向負向)的主觀性文本進行分析,以確定該文本的觀點、喜好、情感傾向1。目前非常流行的 NLP 函式庫 Hugging Face Transformers 中提供了預訓練的 DistilBERT 模型作為情感分析模型。
解決問題的思路是:首先從漢英詞典 Heptagon196/Dict 中選出所有單字條目及對應的英文解釋2。 然後,對於所有單字,使用 ToJyutping 函式庫為單字標註粵語拼音3, 然後據粵語拼音判斷是否該字是否為入聲字4。接下來,對於所有單字,根據其對應的英文解釋,使用預訓練的 DistilBERT 模型判斷該字的情感傾向得分5。最後,比較舒聲字和入聲字的情感傾向平均分。若得分相近,則説明入聲字的情感與舒聲字無明顯差別,否則有明顯差別。
本次實驗使用 NumPy 1.22.3,TensorFlow 2.10.0 及 Hugging Face Transformers 4.18.0 版本。
從漢英詞典中選出所有單字條目及對應的英文解釋的程式較為簡單,此處略去。
情感分析部分的程式如下。
1. 引入函式庫
import ToJyutping
from tqdm import tqdm
from transformers import pipeline
import numpy as np
import re2. 載入情感分析模型
classifier = pipeline('sentiment-analysis')3. 定義情感傾向得分函式
def handle_one_result(result):
if result['label'] == 'POSITIVE':
score = result['score'] * 100
assert score > 50.
else:
score = 100. - result['score'] * 100
assert score < 50.
return score4. 定義輔助函式
def 分块(lst, n):
return [lst[i:i+n] for i in range(0, len(lst), n)]
def 根据粤拼判断入声(粵拼: str) -> bool:
return bool(re.search('[ptk]\d$', 粵拼))5. 讀入單字及其英文解釋,並分塊
汉字_英文列表 = []
英文列表 = []
with open('词表.txt', encoding='utf-8') as f:
for line in f:
汉字, 英文 = line.rstrip('\n').split('\t')
汉字_英文列表.append((汉字, 英文))
英文列表.append(英文)
分块英文列表 = 分块(英文列表, 64)6. 使用情感分析模型得出情感傾向得分
情感分析结果列表 = []
for 英文块 in tqdm(分块英文列表):
情感分析结果块 = classifier(英文块)
情感分析结果块 = list(map(handle_one_result, 情感分析结果块))
情感分析结果列表.extend(情感分析结果块)7. 判斷入聲字,並分別統計舒聲字和入聲字的得分
舒声字得分列表 = []
入声字得分列表 = []
with open('结果.txt', 'w', encoding='utf-8') as f:
for (汉字, 英文), 情感分析结果 in zip(汉字_英文列表, 情感分析结果列表):
粵拼 = ToJyutping.get_jyutping_text(汉字)
if not 粵拼:
continue # 不处理没有读音的情况
是入声字 = 根据粤拼判断入声(粵拼)
if not 是入声字:
舒声字得分列表.append(情感分析结果)
else:
入声字得分列表.append(情感分析结果)
print(汉字, 粵拼, '舒' if not 是入声字 else '入', 英文, 情感分析结果, sep='\t', file=f)8. 計算舒聲字和入聲字的情感傾向平均分,並輸出
舒声字平均分 = np.array(舒声字得分列表).mean()
入声字平均分 = np.array(入声字得分列表).mean()
print(f'舒声字平均分:{舒声字平均分:.2f}')
print(f'入声字平均分:{入声字平均分:.2f}')程式輸出:
舒声字平均分:60.90
入声字平均分:59.42因此,入聲字的情感與舒聲字無明顯差別。
得分最高的前 10 個字:
得分最低的前 10 個字:
可以看到得分最高和最低的前 10 個字都是舒聲字。
得分最高的前 10 個入聲字:
得分最低的前 10 個入聲字:
本次實驗的完整程式碼見 Gist。
(作於 2022 年 4 月 17 日,發佈於 2022 年 4 月 20 日)
https://houbb.github.io/2020/01/20/nlp-qingganfenxi-01-overview↩︎
如果某個條目對應多個解釋,則只選擇第一個。例如「贴」有 to stick; to paste; to keep close to; to fit snugly; allowance 五個解釋,分析時僅選擇 to stick 一個↩︎
對於多音字,ToJyutping 函式庫只返回頻率最高的一個讀音↩︎
有少數字在中古並非入聲字,但在粵語中變為入聲,如「值」。但這類字較少,因此對結果影響不大↩︎
單字與對應的英文解釋的含義可能不完全一致,從而導致情感分析的結果不準確。例如「挽」的英文解釋為 draw,但 draw 還有「繪畫」的意思,而「挽」字無。不過這類字較少,因此對結果影響不大↩︎